Binding Guide (Task Builder 2 & Game Builder)
- Advanced Binding
Overview
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
When building tasks, many configuration settings can be set directly. Whether it's the text of an instructions screen or the time limit for a screen, you can simply set the value you want in the tools:

In the case above, the screen will always have a time limit of five seconds. But this isn't always what we want - we might want different trials to have different time limits. Or we might want to have two experimental conditions with different time limits. Or we might have a task where the time limit changes dynamically depending on the participant's performance. We know we want a time limit, but we want to specify it somewhere else.
Instead of entering a value directly, we can instead dynamically link this field to another source of data - for example, a column in the spreadsheet, or an experimental manipulation. In Gorilla, we call this binding - we bind the field to a data source that allows it to be defined elsewhere. You can bind any configuration setting that has the little link icon ( ).
Sometimes, you may need to store specific values in separate fields in the Store for later retrieval during a task. To achieve this, you'll need to use the Advanced Binding capabilities. The Advanced Bindings enable you to create a 'daisy-chain' of binding where the name of the field is specified in either the spreadsheet or in another field in the Store.
While a simple binding suffices for most tasks - such as storing a count of correct answers across trials - there are situations where the Advanced Bindings are necessary. For example, if you want to store individual responses separately in the Store, so each one can be retrieved later in the task, you will need an Advanced Spreadsheet Binding. Similarly, if you need to capture and store multiple responses on a single screen for later retrieval, you will need an Advanced Store Binding. Many tasks outlined in the From Simple Components to Advanced Functionality guide showcase these Advanced Binding configurations.
Browse the list of topics in the menu to find out more about the different types of binding.
Spreadsheet
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
The most common use case for binding is using the spreadsheet. In both Task Builder 2 and Game Builder, the spreadsheet defines which displays or scenes the participant will see, and in what order - it effectively defines the protocol for the task. For each row in your spreadsheet, the task will perform the display or scene defined for that row:
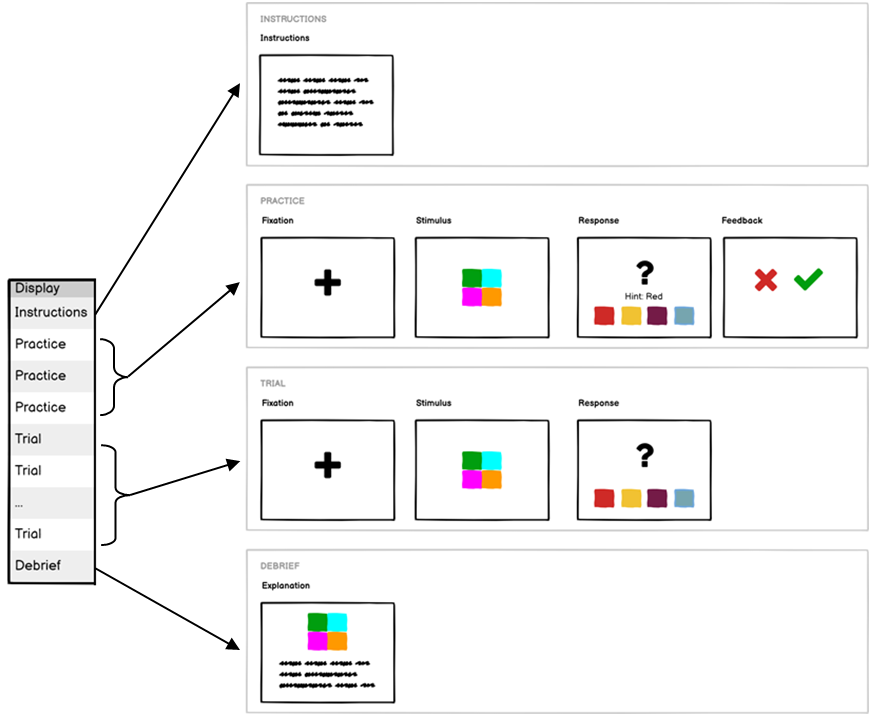
A lot of the time, you'll want to have lots of trials, but have the stimulus be different for each one. You achieve this by binding your stimulus field to the spreadsheet, so that on each trial, it takes its value from a particular spreadsheet column:
To do this, click the binding icon next to the setting you want to bind, and either choose an existing spreadsheet column or create a new one:
You can now upload your stimuli and add them to your spreadsheet. If you go back to your trial and open the Debug tab, you can select a spreadsheet row to preview so that you can check that your bindings are working:
Check out our How To Guides for more information on using the spreadsheet in Task Builder 2 and using the spreadsheet in Game Builder.
Manipulations
This guide is about binding to manipulations in Task Builder 2 and Game Builder. For information on binding to manipulations in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
Manipulations are settings that you can control at the experimental level. Rather than have settings that change trial-by-trial, this allows you to have settings which you can configure differently for different experimental conditions. To give a simple example, you might want to have all your participants do the same task, but have half of them do the task with a longer stimulus presentation time and half with a shorter stimulus presentation time:
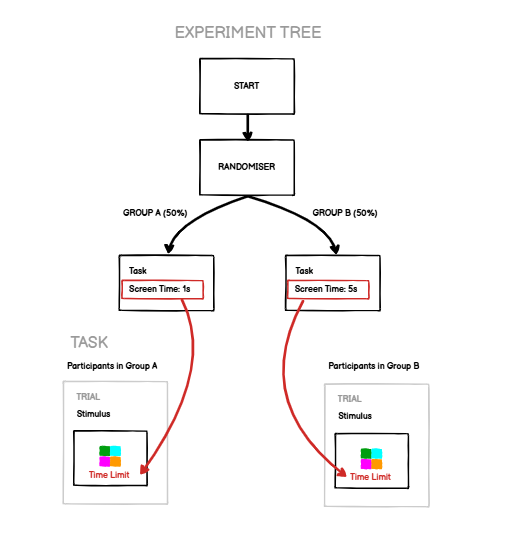
To do this, click the binding icon next to the setting you want to bind, and either choose an existing manipulation or create a new one. When you preview your task, you can set the value for that manipulation to help you test it. When you add your task to an experiment, you can configure manipulations separately for each instance of the task.
Store
This guide is about binding to the Store in Task Builder 2 and Game Builder. For information on binding to the Store in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
Each participant has their own unique Store - data that belongs to them and stays with them for the duration of the experiment. You can think of it as a little backpack or suitcase that each participant carries with them, and you can put values in there and then retrieve them again later. In the first generation of tools, this was referred to as Embedded Data - we've changed the name to Store because we think it's a better term, but it fulfils the same function.
The simplest use-case for the Store is when you want to save a participant's response and then use it later in the task. Note that this is separate from recording responses for your actual experimental data that you download once your participants have finished - participant responses are always recorded in your downloaded data; the Store is purely when you also want to be able to use a particular response later in the task.
For example, imagine a memory task where the participant is asked to specify an animal at the start of the task, and then recall it at the end. We want to check if the participant's recalled response at the end of the task matches their initial response at the start - i.e., whether they recall their response accurately. You would save their initial response to the Store at the start, perform the rest of the task, ask them to enter the animal again at the end, and compare their response to the one from the Store to establish whether they were correct:
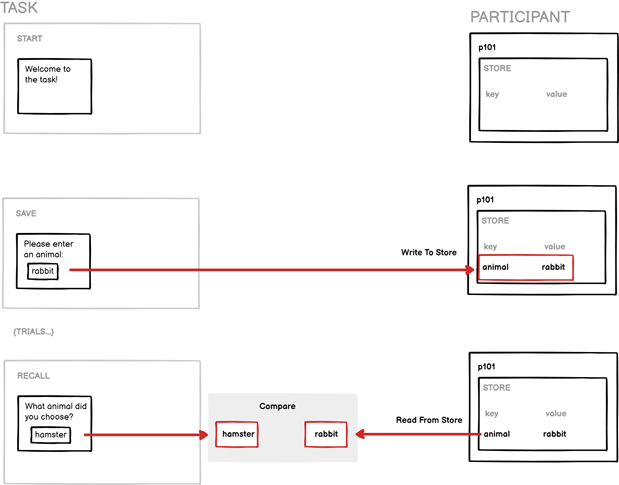
To do this, you first need to tag your response, and then use the Save Response screen component to save the response to the Store. On the recall screen, you can now bind the Correct Answer field of your Scorer component to the same field in the Store:
If you have saved some data to a store field, you may want to check how these values are being updated. When previewing a single screen with DEBUG selected, you can select specific trials of your task to show on the screen preview using dropdown menus. After pressing Play, the sequence of events for the screen will be shown in the DEBUG tab. The DEBUG panel shows how values in the store are being updated in the format ‘Setting field x to value y'.
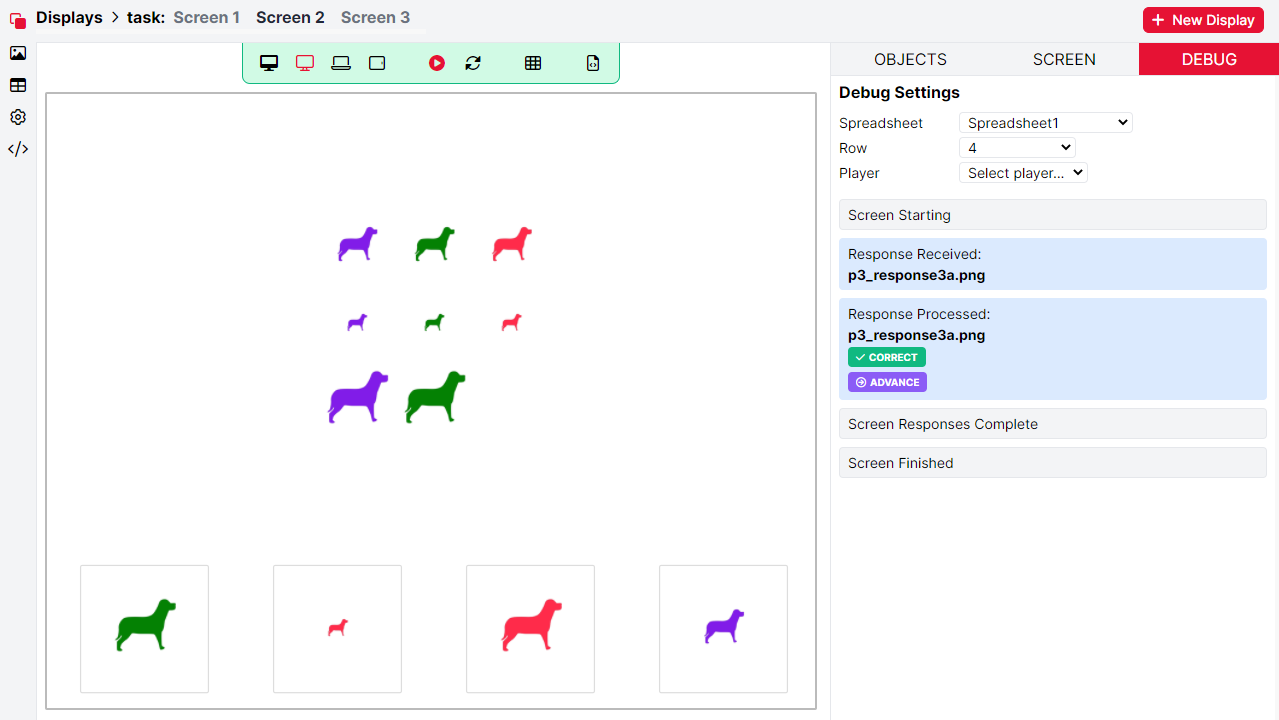
Data in the Store is global by default, and so any values that your task writes to the Store will also be available in future tasks, as well as in the experiment tree. The most common use-case of this is to record a response in a task, and then use that response to branch the participant in the experiment tree.
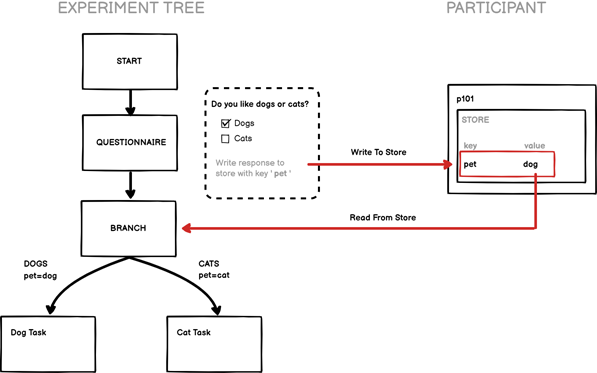
For example, imagine an experiment which first asks participants whether they prefer dogs or cats as a pet, and then directs them to a different task depending on their response - so dog people get one task and cat people get another. In Gorilla, we start with a questionnaire which asks the initial dog or cat question, and we then save this to the Store under the key pet. By the end of the questionnaire, all participants should have one value called pet in their Store, which will either be cat or dog. The next node is a branch node, which looks up the value of pet in the participant's Store, and directs them down the appropriate branch:
Network Store
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
The Network Store is only used in Multiplayer tasks and works in the same way as the Store, but instead of each player having their own separate Store, all players share a single synchronised Store. For example, when Player A writes a value to the Network Store, it is automatically updated for Player B as well.
This is useful for sharing state between players. For example, if you wanted to capture a response from Player A and display it to Player B, you would have Player A write the response to the Network Store, and then bind the text display for Player B to the same field:
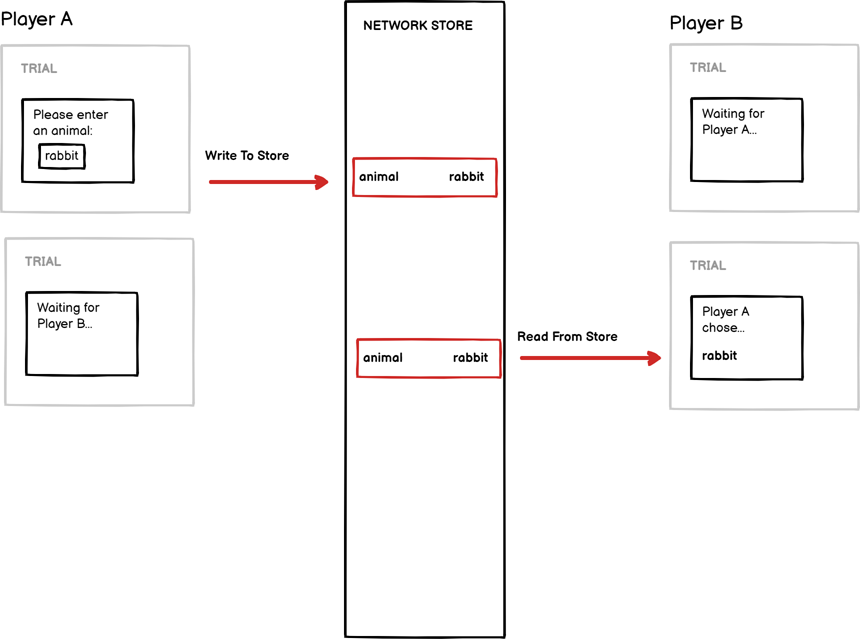
The Network Store only shares information between participants during a multiplayer task; as a result, values saved in the Network Store are not available at the experiment level (for example, in other tasks, questionnaires, or experiment tree control nodes). To use these values at the experiment tree level, you must first save them to the local Store, for example, by adding a Save Data component component to your task.
For more about multiplayer, read the How To: Multiplayer guide for an introduction, and then go through our Step-By-Step guide to build a multiplayer task for yourself.
Changing Stimuli Based on Responses
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
In some tasks, you might show participants a single pre-selected image on each trial. But it's also possible to dynamically change the image shown on a screen based on a participant's response!
In this guide, we will walk through two examples of how to do this. In Example 1, participants drag a slider to see different portion sizes. In Example 2, participants click a button to pump up a balloon. If you want participants to respond using a Dropdown, Multiple Choice, Number Entry, Rating Scale, Slider, or Text Entry component, follow Example 1. Otherwise, follow Example 2.
Example 1: Showing Different Stimuli using a Slider
Use Case: You want participants to change the size, volume, count etc. of a stimuli by moving a slider up and down. For example, as participants move the slider up, they are shown progressively larger meal portions.
To do this, first, create your stimuli outside of Gorilla. These could be images with different colour saturation, audio files with different pitches, or whatever your task needs! Label your stimuli files with numbers, like 'img-1.jpg', 'img-2.jpg' etc. In this example, there are four images with one, two, three, and four cupcakes, so we have four image files labelled cupcake1.jpg, cupcake2.jpg and so on. Then add these stimuli to the Stimuli tab.
In the Spreadsheet, add columns corresponding to the number of stimuli you want a participant to be able to see. So, as we have four images, we create four columns, labeling each column '1' through to '4'.
Next, on the screen you want participants to respond on, add the Slider component. Configure the slider to fit your question. This setup is easiest with fewer possible values. On the Slider component, set a Starting Value for the slider. This will determine what corresponding stimuli is shown at the start, so you may wish to select the lowest or mid-point value. In this example, we have selected '3', to show a mid-point image. Then select 'Show Additional Settings' and then toggle on 'Continuous Polling' and set the polling interval to 500ms. This means the participants' response is checked every 500ms, allowing for quick updates to the stimuli.
Once the slider is set up, add all your relevant stimuli to the same screen. If using Image components, you may wish to stack these images on top of each other, so they are always shown in the same place. Bind the images or audio to the spreadsheet. In this example, we have an Image component called 'Image1' that is bound to Spreadsheet column '1', which has a value of 'cupcake1.jpg'. Repeat this for all stimuli.
We now need to connect the Slider response to the stimuli. We do this by making the images visible or invisible based on the participant's response. On your first Image or Audio component (e.g. Image1), add a Trigger Visible component. Click 'Add', then select 'Screen Start' for the trigger and 'Invisible' for the visibility. Click 'Add' again, then set trigger to 'response' and the response option as '1', toggle on 'Include Actions', set the visibility to 'Visible'. This means, when a '1' response from the Slider comes through, this stimuli will be visible. We next need to make sure the stimuli is invisible for every other response. Click 'Add' again, then set trigger to 'response' and the response option as '2', toggle on 'Include Actions', set the visibility to 'Invisible'. Repeat this step for all response options.
Next, we repeat this step for the other stimuli. You can do this quickly, by clicking on the three dots next to 'Trigger - Visible' and then 'Copy Component'. Go to your other stimuli objects and in the top right, click the three dots and paste component. Make sure to go through the Trigger Visible component and update the visibility, so that Image2 is visible when the response is '2' but invisible when the response is '1' and so on.
Finally, add a component that will progress the screen. This is usually a Continue Button or a Time Limit.
You can find this sample here: Adaptive Slider
Example 2: Showing Different Stimuli using Click Responses
Use Case: You want participants to change the size, volume, count etc. of a stimuli by clicking a button or giving a keyboard response. For example, as participants click a button the size of a balloon stimuli increases.
To do this, first, create your stimuli outside of Gorilla. These could be images with different colour saturation, audio files with different pitches, or whatever your task needs! Label your stimuli files with numbers, for instance, 'img-1.jpg', 'img-2.jpg' and so on. It is important all stimuli files have the same start (e.g. 'img-') and file suffix. In this example, we have labelled the files b1.jpg, b2.jpg, b3.jpg and so on, where b stands for balloon. Then add these stimuli to the Stimuli tab.
Next, add a response option to a screen. Use a Markdown Text and Click Response component to create a button. In the Click Response component, set the response value to match the task. Here, this is 'air' for participants to inflate the balloon.
Then, go to the screen tab and add a Set Field on Start component. Add a new Field called ImageSize and set the value to '1'. This will help set the initial stimuli as the first image or audio file.
On the screen tab also add a Save Data component. Set the criteria to 'Response Value' and enter the response option (e.g. air). Set the Operation as 'Add', value '1', and the Field as the Field you just created in the step above (ImageSize). Together, this means there is a Field in the Store that starts with a value of '1', and every time the relevant button is pressed, 1 is added to the Field's value.
We now need to change the stimuli. Add just one stimuli component (e.g. an Image component). For the stimuli, click the link symbol next to 'Image' or 'Audio' to bring up the binding options and select Custom. Enter the start of your image or audio file names. In this example, this is 'b'. Follow this with '$(store:FIELD-NAME).FILE-SUFFIX, for example, b$(store:ImageSize).jpg. '$(store:ImageSize)' will be replaced by the value of this Field in the Store. We've set it to start at 1, so the first image a participant will see is 'b1.jpg'. As the value of the Field changes with each response, so does the file name that is used.
Finally, make sure participants can click the relevant button multiples times by adding a separate Continue Button.
You can find this sample here: Balloon Analogue Risk Task (BART). This sample also includes lots of other features. To achieve the changing image effect, you don't need to do anything other than what's described in this guide!
Advanced Spreadsheet Binding
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
Advanced spreadsheet bindings allow you to bind components to specific fields in the Store, as defined by the spreadsheet. This setup is useful when you need to store individual responses from each trial in separate fields in the Store. This way, you can later display all responses given across trials.
In a similar way to how we bind content to the spreadsheet to change the stimulus presented on a trial-by-trial basis, in this setup we just change the name of the field in the Store on a trial-by-trial basis. This way, we can ensure each response is saved to a unique field in the Store, so we can easily retrieve each response individually later in the task.
For example, say we have 4 trials in our task and we want to save each response given by participants to the Store so we can give participants a recap of all the responses given throughout the task. We can achieve this by using a Save Response component and utilising its advanced binding settings. To access these settings, toggle the 'Show Advanced Settings' option in the binding window.
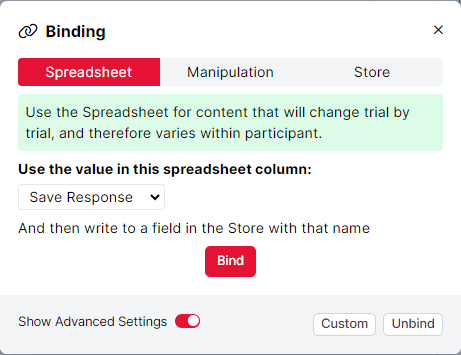
In the example above, we ask Gorilla to look in the spreadsheet column called 'Save Response' and then save the response to the field in the Store defined in this column. In this spreadsheet, we need to list unique values to be the names of the fields in the Store. The response will be saved to the Store under this field name:
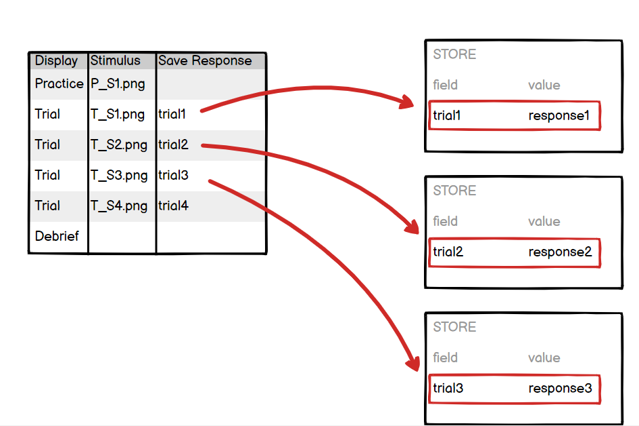
For this example, the response in the first trial is saved to the Store in a field called 'trial1', the response from the second trial is saved to the Store in a field called 'trial2' and so on. This means that we can easily retrieve each of these responses with a simple binding to the Store and the associated response from this trial will be shown.
We have a helpful Response Recap Tutorial which uses this advanced binding setup - this is a great example to see the functionality in action!
Advanced Store Binding
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
Advanced Store bindings allow you to bind components to specific fields in the Store, defined by the value in another field in the Store. The most common use case for this example is if you would like to collect multiple responses on a single screen, and redisplay these responses to participants later in the task.
In order to save each response separately, we need to configure some other components so we can ensure that each response is saved to a unique field in the Store. The easiest way to do this is via the Save Data component. Using this component, we can create a field in the Store called 'responseCount' and each time a response is received on the screen, a value of 1 is added to this field. This means that when the first response is received, there will be a value of 1 in the responseCount field; when the second response is received, the value in the responseCount field will be 2.
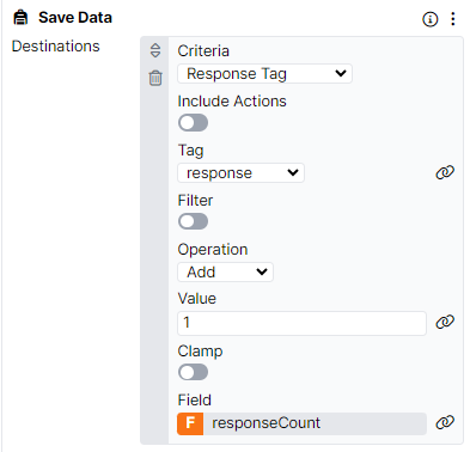
Now that we have configured a way to change the value in the responseCount field, we can use this to save each response given by participants on this screen to a unique field in the Store. We achieve this by using the Save Response component and its Advanced Binding settings. To access these settings, toggle the 'Show Advanced Settings' option in the binding window.
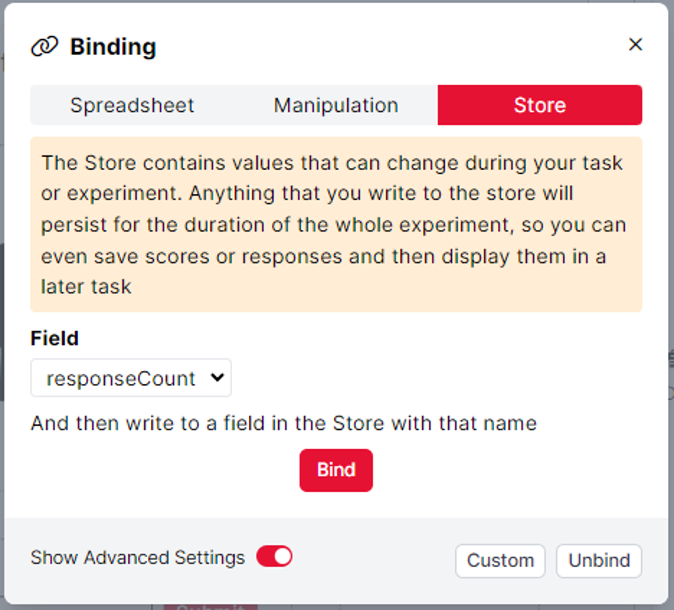
With the binding above, Gorilla will save the response to the Store, and the name of the field where the response is saved will be the value in the responseCount field at that time. For example, when the first response is received the value in the responseCount field will be 1, so the response is saved to the Store under the field name 1. When the second response is received, the value in the responseCount field will be 2, so the response will be saved to the Store under the field name 2, and so forth. With the logic configured via the Save Data component, the value in the responseCount field will always change when a response is received, allowing for every response to be saved to a unique field in the Store.
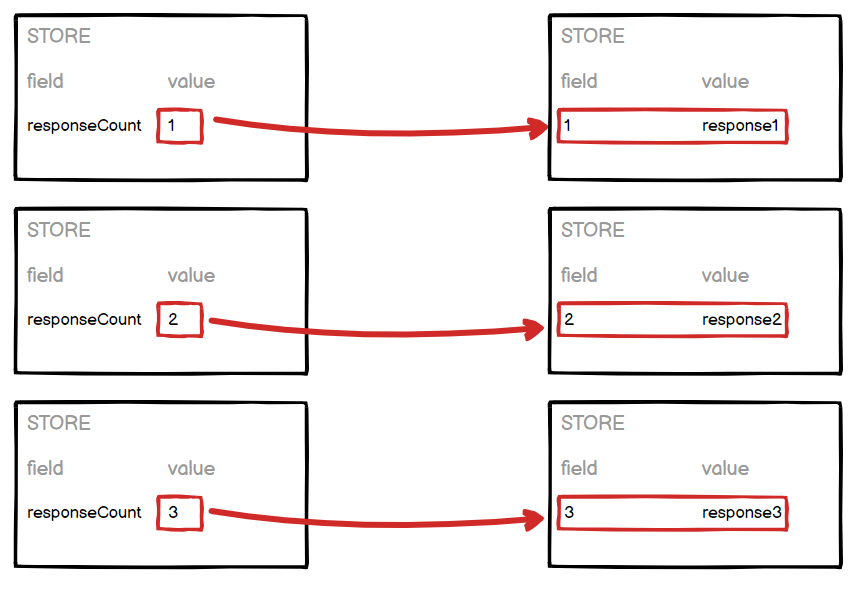
Then, when we want to retrieve the responses saved to the Store in this way, we will need to use a simple Store binding to retrieve the responses saved under the fields 1, 2, 3 and so on.
We have a helpful example of Storing and redisplaying multiple responses from a single screen in our From Simple Components to Advanced Functionality guide. This is a great way to see this set up in action.
Advanced Binding Reference Guide
This guide is about binding in Task Builder 2 and Game Builder. For information on binding in Questionnaire Builder 2, see the Questionnaire Builder 2 Binding Guide.
Advanced Binding can unlock many options when using Gorilla! Regular binding means you specify where the source of the time limit, image, text etc. comes from. For instance, you can specify to look in a spreadsheet column for what text to show. This is great for dynamically changing what you want to show per trial! In most cases, you will only need to use this regular type of binding.
Advanced Binding, adds a layer to this by first taking a value (e.g. text in a spreadsheet column) and then using this value to find another value (e.g. a field in the Store). This allows you to pull information from different spreadsheet columns, save participant's performance to different trial numbers, and many more options. This page describes the most common uses of Advanced Binding. If you want to use a type of Advanced Binding that's not mentioned below, please get in touch with us!
We first recommend checking out our Advanced Spreadsheet Binding and Advanced Store Binding guides. These pages go into more detail about how Advanced Binding works and highlight two of the most common use cases. Once you’re familiar with Advanced Binding, take a look at the tables below to learn more about the different types of binding available.
Custom Binding can be used with regular binding and Advanced Binding, allowing you to type the syntax for the desired binding. This can be used to seamlessly pull in values from the Spreadsheet, Manipulations, or Store fields. For example, in the Markdown Text component you can pipe in text from the a Store field to show participants their score in your task. The custom binding syntax for each Advanced Binding type are shown in the tables below.
Spreadsheet Advanced Binding
This table presents the different Advanced Binding options you can do from the Spreadsheet tab of the Advanced Binding Screen.
| Type | Symbol | Description | Use Case | Example | Custom Binding |
|---|---|---|---|---|---|
| Use that value |  |
This binding counts as Advanced Binding when a default value is also used, otherwise, it’s the same as binding directly to a spreadsheet column. | You want to bind a text component to a spreadsheet column. Throughout the task, the text will mostly be the same word, but on some trials, you want to change the word. You can use this Advanced Binding to set a default value and leave spreadsheet rows blank when you want to use this default value. | Use that Value with a default | ${spread |
| Look for a spreadsheet column with that name | 
| This binding takes the value that is in the selected column, and looks for a second column named after that value. It then returns the value in the same row in the second column. | You want to insert an Attention Check Screen once in each trial block. You can use this binding to search one column for the block number, then look up a column named after the current block number. This allows you to have one display for your trial content, while making sure each block has only one attention check. | Inserting an Attention Check Screen | ${spread |
| Look for a field in the Store with that name | 
| This binding takes the value that is in the selected column, and then looks for a field in the store with that name. It then returns the value stored in that field. | You want to show participants what they previously answered in the same task. You can do this by first saving participant's responses to fields in the Store with the same name as the content in your spreadsheet, then use this binding to look up the relevant spreadsheet value and the matching field in the Store. In the linked example, this type of binding is shown towards the end as custom binding. | Showing Previous Responses | ${store: |
Manipulation Advanced Binding
This table presents the different Advanced Binding options you can do from the Manipulation tab of the Advanced Binding Screen.
| Type | Symbol | Description | Use Case | Example | Custom Binding |
|---|---|---|---|---|---|
| Look for a spreadsheet column with that name | 
| This binding takes the option selected in the Experiment Builder for this manipulation, then looks for a spreadsheet column named after that option, and returns the value in that column. | You want to show different sets of stimuli to groups of participants, then you can use this binding. By having multiple versions of the same task in the experiment tree, you can then set up your manipulation effectively. Next, create columns in the task's spreadsheet that match the options in the manipulation. With this binding, you can then take the manipulation option, and use the text that's in that spreadsheet column. | Spreadsheet Manipulations | ${spreadsheet: |
| Look for a field in the Store with that name | 
| This binding takes the option selected in the Experiment Builder for this manipulation and then looks for a field in the Store with that name. It then returns the value stored in that field. | You want to show some participants the number of their correct answers, and other participants the number of their incorrect answers. You can use this binding: a manipulation with options, ‘correct’ and ‘incorrect’, then set up Scoring and use the Save Accuracy component to save the number of in/correct responses to fields in the store called ‘correct’ and ‘incorrect’. Then, in your experiment, set the manipulation up to, in one node, use ‘correct’ and in another node, use ‘incorrect’. | Manipulations and the Store. | ${store: |
Store Advanced Binding
This table presents the different Advanced Binding options you can do from the Store tab of the Advanced Binding Screen.
| Type | Symbol | Description | Use Case | Example | Custom Binding |
|---|---|---|---|---|---|
| Look for a spreadsheet column with that name | 
| This binding takes the value of a field in the store, then looks for a column in the spreadsheet with the same name. It then returns the corresponding value for that row. | You want to show participants different stimuli based on how they perform in a task. A field in the store can be set to change based on task progression or other responses; then you can use the value stored in that field to look up a correspondingly named spreadsheet column. By having multiple spreadsheet columns with different stimuli, you can control what is shown to a participant. | Staircase with number of reversals | ${spreadsheet: |
| Look for a field in the Store with that name | 
| This binding takes the value of a field in the store, then looks for a second field in the store whose name matches this value. It returns the value stored in the second field. | You want to show participants different stimuli based on how they perform in a task, but what exactly that stimuli is, has been randomised within the spreadsheet. By combining this binding with Stable Random Assignment, you can save the now randomised stimuli to the store and then use another field to to locate the relevant stimuli. Please note, the example task uses custom binding. | Probabilistic Payoffs | ${store: |
Save Components
You can also use Advanced binding with the Save Accuracy, Save Data, Save Reaction Time, and Save Response components. When you do this, you can specify the Store Field to which the data will be saved, using Spreadsheet values, Manipulation options, or other Fields in the store
Note, this binding won’t create a Field in the store that will be in your data download. It will still work during an experiment, but it isn’t saved beyond that. If you want to see the Field and value in your data, you need to create the field elsewhere, such as with the Set Field on Start component or in the settings tab.
| Type | Symbol | Description | Use Case | Example | Custom Binding |
|---|---|---|---|---|---|
| Use the value in this spreadsheet column: {} and write to a Store field with that name | 
| This binding means the data will be saved to a store field with the same name as the value in the selected spreadsheet column. | You want to show participants their earlier responses to specific stimuli. By saving a response to a field in the store with the same name as a stimulus from the spreadsheet (e.g. image.png), we can then easily redisplay both the stimuli and their corresponding response in a later display. | Showing previous responses | ${ |
| Use the value from this manipulation {} and write to a Store field with that name | 
| This binding means the data will be saved to a store field with the same name as the selected Manipulation option. | You want participants to repeat the same task, but save their responses to different fields each time they do the task. You can create an experiment with your task repeated as multiple nodes and the manipulation set to be different in each node. By setting the ‘percentage’ manipulation in the first task node to percentage1, when a participant does this task, their percentage accuracy is saved to a field in the store called “percentage1”. This field can then be used to branch participants into other tasks. | Make Low-Scoring Participants Repeat a Task | ${ |
| Field {} and then write to a Store field with that name | 
| This binding means the data will be saved to a store field with the same name as the value saved in the selected Field in the Store. | You have participants responding to a series of questions and want to redisplay their responses to specific questions later in the experiment. If you have a field such as Response_Count, and save the value 1 to it, you can then use this binding to save a response to the field in the store called 1. You can then repeat this by adding one to the Response_Count field, so it equals 2. You then use this binding to save a participant’s next response to a field in the store called 2, and so on. | Store and re-display multiple responses from a single screen | ${ |