Data Analysis
- Understanding Your Data
- Tidying your data in RStudio
- Tidying your data in Microsoft Excel
- Processing advanced data
Overview
This guide will take you through all the steps you need to handle your Gorilla data.
Check out the list of topics in the menu to find out about file formats, how to understand your data, and exactly what each column in your data file means.
Then find out to process and analyse your data in Microsoft Excel or RStudio with our handy walkthroughs and tutorials.
If you're using mousetracking or eyetracking in the older Task Builder 1, we have specific guides for analysing these using RStudio:
If you want to take a deeper dive into data analysis with Gorilla using real examples of real experimental data, check out Gorilla Academy.
Data Format
Data files
By default, your Gorilla data is provided as a separate file for each node in the experiment tree. This allows you to easily comply with British Psychological Society requirements to keep performance data, demographic data, and identifying data separate.
However, you can optionally override this default and automatically combine data from multiple tasks and/or multiple questionnaires into one file. To do this, select the appropriate checkbox(es) from the 'Combine data' options when you generate your data.
To combine data from tasks with data from questionnaires, you need to match the data up by participant IDs. These guides are here to show you how to do this in both RStudio and Excel.
File types
You can download data in the following formats which can be easily imported into your favourite data analysis software:
- .xlsx (Microsoft Excel Open XML Format Spreadsheet file)
- .csv (Comma Separated Value)
- .csv (Semicolon)
- .csv (Tab)
By default, data will be downloaded as a CSV file, but you can choose any of the above file types instead based on your own preferences. Once you've downloaded your data, you can then open your file in your preferred data processing or statistical analysis package (e.g. SPSS, R/RStudio, or Excel).
Long format vs short format data
Task data is provided in long-format (one row per event), whereas questionnaire data can be downloaded in either long format or short-format (one row per participant):
- Long format data means that every participant has multiple rows. For tasks, this means every relevant timed event (stimuli and responses, for example) in each individual trial occurs on a different row. In questionnaires, each question is on a separate row. This can feel like an overwhelming amount of data, but don't panic; we have resources throughout this guide to walk you through transforming your data into short-format.
- Short format data means that there is only one row per participant, with each question and answer provided in separate columns. However, if you have chosen to combine data from multiple questionnaires into one short-form data file, you'll see multiple rows per participant, with each row of data corresponding to one questionnaire in your experiment.
You can convert long format task data to short format (one row per participant) in various software, but we provide guides for doing this using Pivot Tables in Microsoft Excel, or in RStudio.
Scores calculated in the Scoring tab in Questionnaire Builder 2 are included in both short-form and long-form data. However, other data from the Store in Questionnaire Builder 2, and from the Script widget in Questionnaire Builder 1, are not included in short-form data. If you want to include other Store data, or any data from a script widget, download the long-form version.
Data Separators
When numerical data such as reaction times are recorded in the browser, they are always encoded with the full stop/period (.) as the decimal separator and the comma (,) as the thousands separator. This is what will be uploaded to Gorilla's data stores. However, in many European countries, the roles of these separators are reversed - the comma is the decimal separator and the full stop is the thousands separator. As a result, when opening a data file expecting this encoding type, the numerical data may be parsed incorrectly.
To prevent this, you can take the following steps:
- Generate and download your data file as a CSV. Using this text-based format should prevent any local assumptions being forced onto the file.
- Open a new file in your spreadsheet program and select the 'Import from text/CSV' option.
- When importing the data, there should be an option to specify the decimal and thousand separators. Set these to full stop and comma respectively.
Alternatively, your spreadsheet program's advanced settings should include an option to manually specify the decimal and thousand separators.
Participant Recordings
When running a full experiment, all participant's recording files can be accessed from the 'Download Experiment Data' button on your Experiment's Data page. The zip folder with all your data will include an 'Uploads' folder, containing all of your files. These files are generated when you use specific components, for example:
- Audio Recording
- Canvas Painting (separate files for Canvas Images and Text Data Files)
- Click Painting (for the Click Painting image with or without the background)
- Eye Tracking
- Mouse Tracking
- Screen Recording
- Video Recording
Participant recordings are labelled using the format: [Experiment ID]-[Experiment Version]-[Participant Private ID]-[Tree Node Key]-[Schedule ID]-[the recording file prefix]-[Spreadsheet Index]-[Screen Counter].[File Type]. Spreadsheet Index is the current row number in the spreadsheet (after randomisation) minus 1. More details on the other values can be found in the Data Columns Guide.
Understanding your Data
When you first open your data files it can be intimidating to try and find the information you're looking for. Below are some data examples, with the location of different types of data.
Most Experiment data columns are included in all downloads for completeness, as many are there for informational purposes only. Some columns will be present/absent from your data depending on whether you've included a particular node or nodes. Similarly, for short-format questionnaire data, the inclusion of some columns are dependent on the question types that you used in your questionnaire (such as checkboxes vs radio buttons in a Multiple Choice question). The following is a guide, but is not prescriptive.
If you're looking for detail on what each data column header means, check out our Data Columns guide which lists all of the columns that may appear in your data download, and what the values within them represent.
Questionnaire Builder 2: Long format data
This is what long-format questionnaire data looks like:
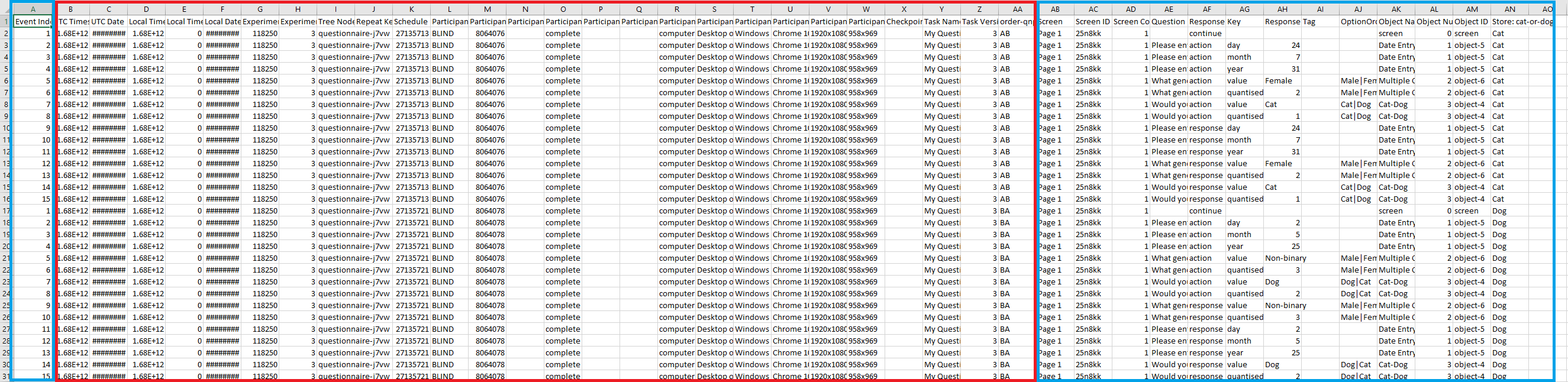
Click to open image in new tab
Most of the columns (highlighted within the red box) are experiment data including participant ID, participant information, and the nodes they passed through. Experiment data columns are included in all task and questionnaire data files.
Columns AB-AN are questionnaire and response data. The columns that will be of interest to most users are the Question and Response columns (columns AE and AH respectively).
The example data file shown in the image includes actions as well as responses in the Response Type column (AF). Actions are a snapshot of what participants' responses looked like when each page was submitted. Responses are the final responses that were submitted. If actions differ from responses, this means the participant went back and changed their answers before completing the questionnaire. By default, Questionnaire Builder 2 data files will only include responses. To include actions as well, when generating your data, select long-form data and check the 'Include additional metrics' option.
If you use scoring or save data to the Store within your questionnaire, you can find this on the far right of your data file, in the column(s) 'Store: [name of field]'.
Questionnaire Builder 2: Short format data
This is what short-format questionnaire data looks like, where each participant has one row of data each:

Click to open image in new tab
This time each participant only has one row of data, and the reduced amount of information makes it easier to say what their responses were to each question. In this case, columns A-AA (highlighted in red) are experiment data, and columns AB-AI (highlighted in blue) are questionnaire and response data. The number of columns with question/response data in will depend on how many questions are in your survey!
Each question is identifiable by its object number in the column header, and there are separate columns for each question. Each response is presented in two ways: the value that the participant chose (such as the text displayed in a multiple choice question) and the quantised response (i.e. whether it was the 1st, 2nd, 3rd... of the available options).
If you use scoring within your questionnaire, you can find this on the far right of your data file, in the column(s) 'Store: [name of score]'.
If you have chosen to combine data from multiple questionnaires into one short-form data file, you'll see multiple rows per participant, with each row of data corresponding to one questionnaire in your experiment.
Task Builder 2: Long format data
This what long-format task data looks like:
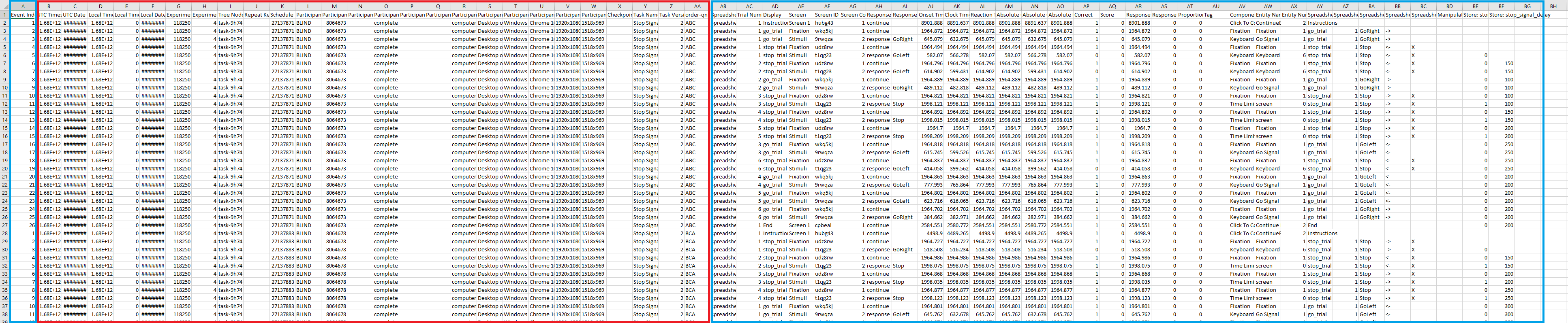
Click to open image in new tab
Many of the columns (highlighted within the red box) are experiment data including participant ID, participant information, and the nodes they passed through. Columns A and AB-BG are task and response data.
Depending on your task, the columns might look different. This data is taken from our Stop Signal Task sample and so has additional columns that are task-specific, such as data that we asked Gorilla to save to the store (column BF).
Generally, the important columns for most researchers in task data are Reaction Time (column AL) and Correct (i.e. accuracy, column AP). It's also useful to use any metadata that helps you identify the trial type or condition depending on the exact nature of your task which you can use to filter your data e.g. Display (column AD), Screen (column AE), and Component Name (column AV).
Experiment data columns are included in all task and questionnaire data files.
Legacy tooling
Questionnaire Builder 1: Long format data
This is what long-format questionnaire data looks like in our older Questionnaire Builder 1:

Click to open image in new tab
Most of the columns (highlighted within the red box) are experiment data including participant ID, participant information, and the nodes they passed through. Columns A, AC, and AD are Question and Response data.
Questionnaire Builder 1: Short format data
This is what short-format questionnaire data looks like in our older Questionnaire Builder 1:

Click to open image in new tab
Most of the columns (highlighted within the red box) are experiment data including participant ID, participant information, and the nodes they passed through. Columns AB-AJ are question and response data. The number of columns with question/response data in will depend on how many questions are in your survey!
Task Builder 1: Long format data
This is what long-format task data looks like, where each participant has one row of data each:
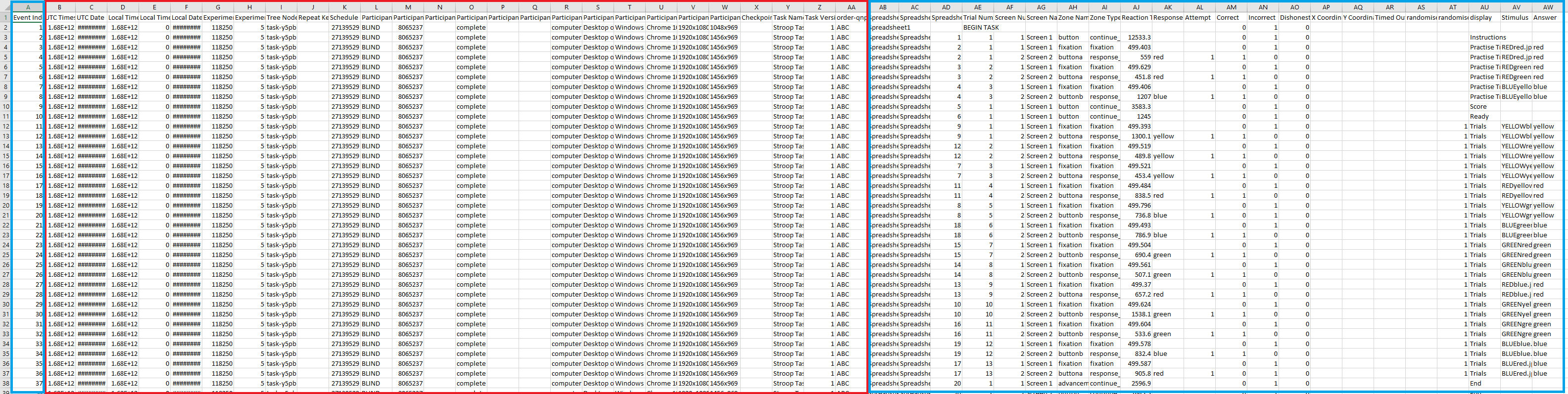
Click to open image in new tab
Most of the columns (highlighted within the red box) are experiment data including participant ID, participant information, and the nodes they passed through. Columns AB-AW are task information and response data.
Depending on your task, the columns might look different, especially if you have included extra metadata in your Task Spreadsheet.
Generally, the important columns for most researchers in task data are Reaction Time (column AJ) and Correct (i.e. accuracy, column AM). It's also useful to use any metadata that helps you identify the trial type or condition depending on the exact nature of your task which you can use to filter your data e.g. Display (column AU), Screen (column AG), and Zone Name/Zone Type (column AH/AI).
Experiment data columns are included in all task and questionnaire data files.
Data Columns
This page lists the columns that may be present in your data download, and what the values within them represent. Experiment data columns are present in both Questionnaire and Task data files.
On this page you will find:
- General experiment columns (present in both Task and Questionnaire data files)
- Questionnaire Builder 2 columns (long-format)
- Questionnaire Builder 2 columns (short-format)
- Task Builder 2 columns
- Legacy tooling
- Questionnaire Builder 1 columns (long-format)
- Questionnaire Builder 1 columns (short-format)
- Task Builder 1 columns
General experiment columns (present in both Task and Questionnaire data files)
In all instances below key will be replaced in your data by the actual key of that node, which you can find in the Experiment Tree. For example, in the image below, the key for this Branch node would be bj8a.
| Column Name | Description |
| Event Index | This is a counter created by the task or questionnaire that the participant is in |
| UTC Timestamp | The exact date and time in UTC milliseconds (UTC x 1000) when this metric was received. This is an absolute timestamp in Unix time, i.e., measured in milliseconds since midnight on 1st January 1970. Historically, this column denoted the timestamp when data was received by Gorilla's servers, and so could slightly differ from the Local Timestamp column. Now, the two columns are identical. |
| UTC Date and Time | The exact UTC date and time from column 'UTC Timestamp', but in a human readable format (DD/MM/YYYY HH:MM:SS) |
| Local Timestamp | The exact date and time in UTC milliseconds (UTC x 1000) when this metric was received. This is an absolute timestamp in Unix time, i.e., measured in milliseconds since midnight on 1st January 1970. Identical to UTC Timestamp column above. |
| Local Timezone | The time difference (in hours) between the participant's timezone and UTC |
| Local Date and Time | The exact date and time in a human readable format (DD/MM/YYYY HH:MM:SS) in the participant's local timezone. This will equal the UTC Date and Time plus the offset given in the Local Timezone column |
| Experiment ID | Unique key identifying the experiment |
| Experiment Version | The version of the experiment |
| Tree Node Key | The unique key for this tree node as shown in the Experiment Tree. This allows you to combine files without losing track. |
| Repeat Key | The unique key for the repeat node in the format 'repeat-key#1' for the first iteration and 'repeat-key#2' for the second and so on. This allows you to combine files without losing track. |
| Schedule ID | Unique key identifying the schedule, which corresponds to a particular participant performing the task or questionnaire associated with a particular tree node |
| Participant Public ID | Unique ID representing this participant. This is visible on the Participants tab of the Experiment Builder, and so is hidden for blinded experiments |
| Participant Private ID | A unique anonymous ID automatically generated by Gorilla representing this participant. |
| Participant Starting Group | The group that the participant started in. Used for experiments with multiple start nodes. |
| Participant Status | The participant’s completion or rejection status. |
| Participant Completion Code | Completion code that was shown to the participant. Used for validating completions on third party recruitment services (e.g. MTurk) |
| Participant External Session ID | External session ID provided by third party recruitment services (e.g. Prolific) |
| Participant Device Type | Information about a participants device type; this will be either 'computer', 'mobile', or 'tablet'. |
| Participant Device | This column gives more detailed information about a participant's device, the detail of information here will depend upon the device and settings of the device owner. For example, if available it will list type of mobile device in use. |
| Participant OS | This column gives information about a participant's Operating System (OS) e.g. Windows 10 |
| Participant Browser | This column gives information about a participant's browser type and version. |
| Participant Monitor Size | This column gives information about a participant's monitor size in pixels: width x height. |
| Participant Viewport Size | This column gives information about a participant's viewport size in pixels: width x height. The viewport size is the effective size of a browser window, minus the browser header bar and any OS navigation bar at the top and bottom or sides of the screen. The height should be smaller than the monitor size, but the width is usually the same size. The value should also stay the same size throughout a participants experiment, if it does not it indicates that a participant is resizing the window during your experiment which might be a possible indication of divided attention that you may wish to factor into your analysis. |
| Checkpoint | Name of the last checkpoint that this participant went through |
| Room ID | ID of the room the participant is assigned to (only relevant for Multiplayer tasks) |
| Room Order | Position of this participant within the order of players in the room, starting from 0 for Player 1 (only relevant for Multiplayer tasks) |
| Task Name | The name of the current task |
| Task Version | The version of the current task |
| allocator-key | The branch that this Allocator node assigned the participant to |
| randomiser-key | The branch that this Randomiser node assigned the participant to |
| branch-key | The branch that this Branch node assigned the participant to |
| order-key | The order that this Order node assigned the participant |
| switch-key-time-primary | This is the total time (in ms) the participant spent on a primary switch task. |
| switch-key-percentage-primary | This is the time the participant spent on a primary switch task displayed as a percentage. |
| switch-key-time-secondary | This is the total time (in ms) the participant spent on the secondary switch task. |
| switch-key-percentage-secondary | This is the time the participant spent on the secondary switch task displayed as a percentage |
| switch-key-switches | This is a count of the total number of switches a participant made between the primary and secondary tasks. |
| counterbalance-key | The spreadsheet column used by the counterbalance node. |
| checkpoint-key | Each Checkpoint Node produces its own column. When a participant passes through the Checkpoint, the name of the Checkpoint will appear in its column. |
| quota-key | The status of the Quota Node that this Quota Node assigned to the participant. |
Questionnaire Builder 2 columns (long-format)
This is for long-format data only. Every questionnaire data file will also include the experiment information columns shown above.
| Column Name | Description |
| Page | The page number. If you randomise the page order for participants, you will still see the page number as specified in the Questionnaire Builder. |
| Page ID | A randomly generated ID that is unique to each specific page |
| Page Counter | The ordinal (1st, 2nd, 3rd etc) page number i.e. the order that participants saw the pages. Especially useful data if you randomised the page order. |
| Question | The question text as written by the researcher. |
| Response Type | This will either be continue, action, info, or response and log the interactions that participants had with the questionnaire. The continue response type logs each time the 'Next' button was pressed. The action response type logs what the participant's response was when the current page was submitted (if the object allows this to be recorded). Actions will only appear in your data if you ticked the 'Include additional metrics' box when generating your data. The info response type logs audio and video start/finish events. Anything tagged with response indicates the final answers that participants submitted to all questions and is likely to be the main response type that most researchers are interested in. |
| Key | Information about the type of data in the response so that you can choose to filter your data by the data type you're most interested in. When the key is Value the Response column will show the exact response that the participant gave. This will either be one of the response options that you, the researcher, supplied, or it will be a text response. If you've selected to use separate responses and labels then it will show the Response that you coded it as rather than the Label that the participants saw. When the key is Quantised this will be a number representing the option number that the participant selected. For example if there are 5 options in a dropdown menu and the participant chose the third option, it will say '3'. In the Date Entry object, the Key specifies the specific piece of data in the Response column e.g. day, month, or year. In the Ranking Scale object, the Key specifies the final position the response was dragged into: 0 = top, 1 = second-from-top, and so on. |
| Response | Usually the response given by the participant. When the response type is info, the response will be an event. Events include 'BEGIN', when the participant starts the questionnaire, 'END', when the participant finishes the questionnaire, and media file events (e.g. 'audio started'). If your subscription gives you access to bot detection features, you may also see the following events: 'COPY', if the participant copies text from the experiment tab 'PASTE', if the participant pastes text into the experiment tab 'TAB_HIDDEN', if the participant switches to another tab in the browser window 'TAB_VISIBLE', if the participant switches back to the experiment tab. |
| Tag | Any custom tags that you've assigned to responses. For rows where the 'END' response is received, the Tag column will contain the time taken to complete the questionnaire in milliseconds. |
| OptionOrder | The order that the response options were presented to the participant, separated by the pipe symbol. This is useful if you randomised the response option order. |
| Object Name | The name of the object. |
| Object Number | The ordinal object number for each page. If the object order is randomised, this number will still correspond to the order that you see the objects in the questionnaire builder. |
| Object ID | The unique ID for this object which can be found at the top right of the object in the questionnaire builder. |
| Store: field-name | If you've saved any data to the store, it will appear in a column with the field name that you specified. |
Questionnaire Builder 2 columns (short-format)
This is for short-format data only. Every questionnaire data file will also include the experiment information columns shown above.
In all instances below the X will be replaced with the actual object ID number of the relevant component in your questionnaire. You can find the object ID within the Questionnaire Builder at the top-right of the component settings. In the below example, the object ID is '6'.
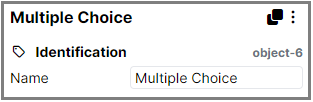
| Column Name | Description |
| ObjectName object-X Value / ObjectName object-X Response | This will show the exact response that the participant gave. This will either be one of the response options that you, the researcher, supplied, or it will be a text response. If you've selected to use separate responses and labels then it will show the Response that you coded it as rather than the Label that the participants saw.If you have multiple items within one object, such as in the Rating Scale or Text Input components, you will see also see the item text in the column name instead of the word 'Value'/'Response'. For the Ranking Scale object, the left-to-right order of these columns will correspond to the original order in which you entered the options in the Questionnaire Builder. The response that was dragged into top position will then be listed in the first column, the response that was dragged into second position in the second column, and so on. |
| ObjectName object-X Quantised | Where applicable, this will be a number representing the option number that the participant selected. For example if there are 5 options in a dropdown menu and the participant chose the third option, it will say '3'.If you have multiple items within one object, such as in the Rating Scale or Text Input components, you will see also see the item text in the column name before the word 'quantised'. |
| ObjectName object-X QuestionText OptionName | This is similar to 'object-X Value', but the specific question text and/or response option will be shown in place of 'Value'/'Response'. For the Consent Form object, and Multiple Choice objects where multiple answers are allowed, each response will be coded as a 1 (the participant selected this option) or a 0 (the participant did not select this option). |
| ObjectName object-X Other | If the participant chose the 'Other' option, such as in a multiple choice question, this will display the text that they entered. |
| ObjectName object-X Day | If you've used the Date Entry object, this column will show you the day the participant selected. |
| ObjectName object-X Month | If you've used the Date Entry object, this column will show you the month the participant selected. |
| ObjectName object-X Year | If you've used the Date Entry object, this column will show you the year the participant selected. |
| ObjectName object-X Hours | If you've used the Time Entry object, this column will show you the hours the participant selected. |
| ObjectName object-X Minutes | If you've used the Time Entry object, this column will show you the minutes the participant selected. |
Task Builder 2 columns
Every task data file will also include the experiment information columns shown in the table at the top of this page.
| Column Name | Description |
| Spreadsheet | DEPRECATED - this column will no longer appear in datasets generated after 14th July 2025. In previously generated datasets, this refers to the name of the spreadsheet set at the experiment tree level (for example, by a manipulation). This makes it identical to the Manipulation: Spreadsheet column |
| Current Spreadsheet | The name of the spreadsheet in use on the current trial. This may differ from the Spreadsheet column if the task uses Change Difficulty - Spreadsheet or Jump to Spreadsheet |
| Trial Number | Within each display, this column shows the trial number. Trial numbers increment every time the Task Builder task moves onto a new row in the spreadsheet, but counts up separately for each display |
| Display | The name of the current display |
| Screen | The name of the current screen within the display |
| Screen ID | A randomly generated ID that is unique to each screen |
| Screen Counter | Which number screen within the current display the data on this row pertains to |
| Response Type | action - this response type is used to log anything relevant the participant did but which doesn't constitute a final response, such as moving the a slider or interacting with the canvas painting object continue - this signals when the screens ends, whether that be due to a participant action/response or a time limit, for example info - this gives additional information about events such as the start and end of the task, audio/video events, or when the response window opens if it was set manually response - the submitted response (these may overlap with actions) timedOut - signals the end of any sort of timed event, such as a time limit on the screen or the end of a trigger's duration |
| Response | The response given by the participant. This may be a response option specified by you, the researcher, or a free text response. When the response type is info, the response will be an event. Events include 'BEGIN', when the participant starts the task, 'END', when the participant finishes the task, and media file events (e.g. 'audio started'). If your subscription gives you access to bot detection features, you may also see the following events: 'COPY', if the participant copies text from the experiment tab 'PASTE', if the participant pastes text into the experiment tab 'TAB_HIDDEN', if the participant switches to another tab in the browser window 'TAB_VISIBLE', if the participant switches back to the experiment tab. |
| Context | (When using the AI Chat Box component) Whether the response in the current row was generated by the AI or the participant. (When using the Trigger - AI component) The prompt that generated the current AI response. |
| Onset Time | Refers to the time that the response started, in milliseconds. This will be identical to the Reaction Time, except for responses that have a duration: for example, drag-and-drop, or typing into a text entry box. Here, Onset Time = when the participant started their response (clicked the Draggable, or started typing in the box). For the total duration of the response, see the Response Duration column. Time is measured from the start of the current screen, unless using the Trigger - Response Window component with a Manual Response Window, in which case time is measured from when the Response Window opens. |
| Clock Time | Refers to the time (in milliseconds) that the screen most recently updated prior to the current Reaction Time. The time between updates depends on the refresh rate of the participant's display. Time is measured from the start of the current screen, unless using the Trigger - Response Window component with a Manual Response Window, in which case time is measured from when the Response Window opens. |
| Reaction Time | Refers to the time (in milliseconds) that the response was submitted. In most cases, this is the data you're interested in! Time is measured from the start of the current screen, unless using the Trigger - Response Window component with a Manual Response Window, in which case time is measured from when the Response Window opens. For rows where the Response is 'END', the Reaction Time column will contain the time taken to complete the entire task in milliseconds. |
| Absolute Onset Time | Refers to the time that the response started, in milliseconds. This will be identical to the Absolute Reaction Time, except for responses that have a duration: for example, drag-and-drop, or typing into a text entry box. Here, Absolute Onset Time = when the participant started their response (clicked the Draggable, or started typing in the box). For the total duration of the response, see the Response Duration column. For all Absolute metrics, time is measured from the start of the current screen, even if you are using the Trigger - Response Window component with a Manual Response Window. |
| Absolute Clock Time | Refers to the time (in milliseconds) that the screen most recently updated prior to the current Absolute Reaction Time. The time between updates depends on the refresh rate of the participant's display. For all Absolute metrics, time is measured from the start of the current screen, even if you are using the Trigger - Response Window component with a Manual Response Window. |
| Absolute Reaction Time | Refers to the time (in milliseconds) that the response was submitted. For all Absolute metrics, time is measured from the start of the current screen, even if you are using the Trigger - Response Window component with a Manual Response Window. |
| Correct | Whether this response was judged as correct. 1 means the answer was correct, and 0 means the answer was incorrect. |
| Response Onset | DEPRECATED - this column will no longer appear in datasets generated after 14th July 2025. In previously generated datasets, the contents are identical to the Onset Time column - see definition above |
| Response Duration | Refers to the time elapsed (in milliseconds) between the time a response started and the time the response was submitted. This will be 0, except for responses that have a duration: for example, drag-and-drop, or typing into a text entry box. Here, Response Duration = Reaction Time minus Onset Time (see above). |
| Proportion | If you're using mousetracking and eyetracking this will tell you the proportion of time the participant spent with their gaze or their mouse cursor over the corresponding object listed in the 'Response' column |
| Tag | The corresponding Tag for this response if you have set one |
| Component Name | The name of the component (set by Gorilla) |
| Object Name | The name of the object that produced this metric. This corresponds to the name given in the Objects Tab in the task structure |
| Object Number | A number that corresponds to the object's position in the list in the Objects Tab in the task structure |
| Object ID | A unique identifier for that object generated by Gorilla. You can find it on that object's settings in the task builder |
| Spreadsheet: column-name | You will likely see multiple columns in your data like this. The show a copy of the data that was in your Task Spreadsheet for each trial. 'column-name' refers to the name of the column in your Task Spreadsheet |
| Manipulation: Spreadsheet | The name of the spreadsheet set at the experiment tree level (for example, by a manipulation) |
| Manipulation: manipulation-name | The value of the manipulation 'manipulation-name' |
| Store: field-name | If you make use of the Store, you will see a column for each Field that you create in the store. The data will show the value that is in that Field in the Store on each row |
Legacy tooling
Questionnaire Builder 1 columns (long-format)
Every questionnaire data file will also include the experiment information columns shown in the table at the top of this page.
| Column Name | Description |
| Question Key | The Question Key (i.e. Response-1). This Key may be -quantised – A numeric version of a text response i.e. the first option on a Likert Scale. |
| Response | The response given by the participant |
Questionnaire Builder 1 columns (short-format)
| Column Name | Description |
| Name-of-your-Question-Key | Response to a widget. In the case of consent boxes, 1 indicates consent. |
| (Name-of-your-Question-Key) -text | If your question has an ‘Other (please specify) option, this column represents any typed response |
| (Name-of-your-Question-Key) -quantised | If you are using a Dropdown widget, a Likert scale, or Radio buttons, this a number representing the option they selected. e.g. Option 1 would be represented as 1. |
| (Name-of-your-Question-Key) - 1 | If you are using a checklist widget, this represents the first option you give on the checklist. If there is a response in this column, the participant has selected this option. If you are using a ranking widget, this represents the first ranked option |
| (Name-of-your-Question-Key) -2 (ect) | If you are using a checklist widget, this represents the second option you give on the checklist. If there is a response in this column, the participant has selected this option. If you are using a ranking widget, this represents the second ranked option |
| (Name-of-your-Question-Key) -year | For Date Entry widgets, contains the year given as a response or, if 'Retrieve as Age' is selected, the number of years between the year given as a response and the year in which the participant completed the Questionnaire. |
| (Name-of-your-Question-Key) -month | For Date Entry widgets, contains the month given as a response, or, if 'Retrieve as Age' is selected, the number of months between the month given as a response and the month in which the participant completed the Questionnaire. |
| (Name-of-your-Question-Key) -day | For Date Entry widgets, contains the day (numerical - of the month) given as a response, or, if 'Retrieve as Age' is selected, the number of days (numerical - of the month) between the day given as a response and the day in which the participant completed the Questionnaire. |
| (Name-of-your-Question-Key) -inmonths | For Date Entry widgets, contains the total time in months between the date given as a response and the date on which the participant completed the Questionnaire. |
| (Name-of-your-Question-Key) -hour | For Time Entry widgets, contains the hour given as a response. |
| (Name-of-your-Question-Key) -minute | For Time Entry widgets, contains the minute given as a response. |
| (Name-of-your-Question-Key) -mixed | If you are using a Mixed-entry widget, this column will hold any ‘selected’ rather than typed responses. If your participant has typed a response, this will appear in a different column, and the -mixed column will be empty. |
| End Questionnaire | The number of milliseconds it took your participant to complete the Questionnaire. |
Task Builder 1 columns
| Column Name | Description |
| Spreadsheet Name | The name of the spreadsheet used |
| Spreadsheet Row | The row of the spreadsheet being displayed. |
| Trial Number | The trial number for this trial. Trial numbers increment every time the task builder task moves on to a new row in the spreadsheet. |
| Screen Number | Screen number within the current display |
| Screen Name | Screen name within the current display |
| Zone Name | Name of the zone that generated this metric |
| Zone Type | Type of the zone that generated this metric |
| Reaction Time | Time (in milliseconds) between the start of the current screen and when this metric was generated |
| Response | The response that was given, if any |
| Attempt | Which attempt at the correct answer this response represents (used when multiple responses are enabled) |
| Correct | Whether this response was judged as correct. 1 means the answer was correct, and 0 means the answer was incorrect. |
| Incorrect | Whether this response was judged as incorrect |
| Dishonest | Produced by the Feedback (Accuracy) Zone. A 1 in this column indicated that dishonest feedback was given. |
| X Coordinate | If using the Click Painting Zone, This will be the position of the click (X coordinate) relative to the original image (regardless of rescaling) in pixels. |
| Y Coordinate | If using the Click Painting Zone, This will be the position of the click (Y coordinate) relative to the original image (regardless of rescaling) in pixels. |
| Timed Out | Whether this response was given as a result of a time out (rather than action on the part of the participant) |
| All remaining columns | These are copies of the spreadsheet row shown to the participant |
Time on Task
When reviewing your data output, you'll see additional rows for each participant at each node. These rows mark when participants begin and end the task.
These rows can be identified by the value in the Response column: either BEGIN or END. Each row includes a timestamp. The END row also includes a Reaction Time value in the Reaction Time column. This is calculated as the time elapsed since the corresponding BEGIN timestamp.
This tells you how long the participant spent completing that specific node (e.g. a task), not the entire experiment.
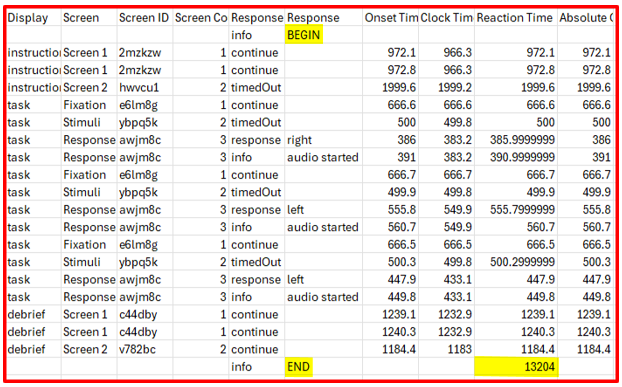
The above explanation applies to data from Task Builder 2, Game Builder, Shop Builder. For Questionnaire Builder 2, you will need to download your data in long format to find the time on task information - this will be recorded to the Tag column in the data output.
From Gorilla to Tidy Data
One of our users, Dr Emma James, has put together a step-by-step guide to data processing using the tidyverse package with RStudio.
This tutorial shows you how to set up the tidyverse in RStudio, read in your data, filter out anything you don't need, and calculate averages.
It also explains how to deal with more than one experimental condition, combining output files, and reshaping your dataset!
The tutorial can be found on Emma's site.
R Overview
R is a programming language that many researchers use for transforming and manipulating data. It is also used to perform statistical analyses.
RStudio is what's known as an Integrated Development Environment (IDE), which just means that you can use the RStudio programme to write and edit code in R.
This walkthrough will get you started with R and RStudio so that you can use it to transform your Gorilla data files ready for statistical analysis.
Downloading and Installing R
R:
- Go to www.r-project.org
- Click the download R link under the “Getting Started” header.
- Select a mirror - you want to pick one that's relatively close to your location.
- Depending on your operating system, click on the Download R for Windows/Download R for Linux/Download R for (Mac) OS X link at the top of the page.
- Click the base link at the top of the page.
- Click the Download R [version number] link at the top of the page.
- Follow the installation instructions.
Downloading and Installing RStudio
RStudio:
- Go to https://posit.co/products/open-source/rstudio/
- Scroll down until you see 'Open Source Edition', then click 'Download RStudio Desktop'
- Click 'Download RStudio'
- Click 'Download RStudio Desktop for [your operating system]'
- Follow the installation instructions.
Opening a New Script in R
When you open Rstudio, you will see a box on the left called Console, a box in the upper right with Environment and History, and a box in the lower right with Files, Plots, Packages and Help. To input commands easily, you will need to open a fourth box, called a Script.
A script is like a document in which you can write and save code. The code in your script can be run easily and repeatedly. You can also copy and paste code from others into your own script, and export your script as a .R file so others can use it.
To open a new script, press the Open New icon in the top left hand corner, then select R Script.
This is your new script. You can write your code or copy and paste code from others into here.
Getting Started with R
The script below allows you to get started with your Gorilla data in R. It explains how to import your file and how to tidy the data.
This is important, as sometimes, when you download the available CSV data from your experiment, there is a lot of files with a lot of data - which can be overwhelming!
Adding the script below to R makes it easy to start analysing your data by tidying it and making it more manageable.
To use the script below, copy and paste everything in the box into the top left-hand section of your new RStudio script. Then follow the instructions written in the comments of the script itself (comments begin with a “#”).
Pressing CTRL+ENTER will run the line of code you are currently on and move you to the next line. Making your way through the code using CTRL+ENTER will allow you to see how the dataset gradually takes shape after every line of code – this is also a good way of easily spotting any errors if you encounter them whilst running the script.
CTRL+ENTER will also run any highlighted code, so if you want to run the whole script together, highlight it all and press CTRL (or Command ⌘ on a Mac) +ENTER You can also press CTRL (or Command ⌘ on a Mac) +ALT+R to run the entire script without highlighting anything
We are constantly updating our R support pages. For more information about columns in Gorilla data specifically, please consult our support page which contains guides on data columns.
Combining Task and Questionnaire Data in R
When you generate your Gorilla data, you can choose to automatically combine data across all tasks or across all questionnaires. However, sometimes you might need to combine data from a task with data from a questionnaire into a single CSV file. Adding the Script below to R makes it easy to do this.
This script reads in one task data file and one long-format questionnaire data file, selects the Keyboard Response responses from the task and the Number Entry response from the questionnaire, and combines this information into one file by matching up the participant IDs.
You can easily adapt it to select different responses from your task and questionnaire data by changing the specified Component Name/Object Name, or using the Object ID column as a filter instead.
Combining CSVs of tasks and questionnaires:
Now you should have a new CSV in the folder you specified as your working directory called "final_combined.csv". This contains all the data you selected from your task and your questionnaire, matched by participant ID.
Long-to-Short Data Transformation using R
To use the script below, copy and paste everything in the box into the top left-hand section of your new RStudio script. Then follow the instructions written in the comments of the script itself (comments begin with a ‘#’).
The scripts below show how to transform your task data from long- to short-format data with some basic data processing. You shouldn't need to do this with your questionnaire data because you can choose to have the questionnaire files in long- or short-format when you download your data!
Task: long to short data transformation
Now you should have a new CSV in the folder you specified as your working directory called "Task_Short_Format.csv” with accuracy as a proportion and the mean RT in milliseconds for each experimental condition, and each participant should only take up one row of data.
Worked Examples of R analysis
We cover plenty of worked examples of data analysis using R in our Gorilla Academy!
Browse through the lectures and video walkthroughs on the Gorilla Academy page.
Excel Overview
Excel can be used to transform and clean your data.
This walkthrough will show you how you can use Excel to filter and clean your data, allowing you to choose only the information you may need.
It also highlights how Excel's pivot tables can be used to get your data in the format you want.
It's worth mentioning that pretty much anything you can do here in Excel can also be done in Google Sheets or open source spreadsheet software.
Clean and Filter Your Data using Excel
The raw CSV file you download from Gorilla contains a lot of information that you probably won't need. We want to give you a complete picture of your participant data, so if you happen to be interested in e.g. the local time when a participant completed your experiment, that information is available to you. However, you are probably only going to be interested in a few specific metrics.
The video below will walk you through what the different columns in your data file are, and how you can filter your data to view the information you need.
NB: The below video was made using data from the Legacy Tool Task Builder 1. The information contained is still accurate, but some of the column names will be a little different. For example, you'll no longer see the columns 'Zone Name' or 'Zone Type' because Task Builder 2 doesn't use zones. In Task Builder 2 data you'll find the same sort of information in the 'Object Name', 'Component Name', and 'Response Type' columns instead.
Length (mins): 2:50
You can also use Excel's filtering function to get rid of rows you don't need in your data. In this example, we are working with questionnaire data, but we are not interested in any ‘quantised’ data. Therefore, we want to remove all data rows which are of the form ‘quantised’ from our questionnaire data. Here’s how to do this in 10 quick steps!
- Open your Gorilla data file in Excel. It will look something like this:
- Navigate to the Data tab:
- Click somewhere within the data, then click on the Filter button:
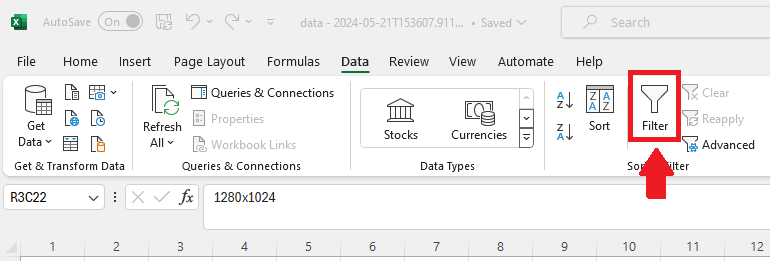
You will now see mini arrows (filter arrows) at the top of all your columns like this:
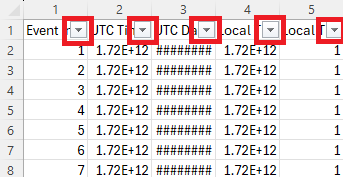
- Navigate to the column which contains the information that identifies the data you want to remove. The column that identifies whether data is quantised or not is the 'Key' column. (If you used Questionnaire Builder 1 to collect your data, the relevant column will be called 'Question Key'.)
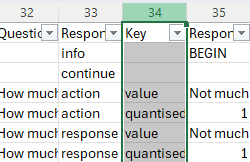
- Click the filter arrow for the Key column:
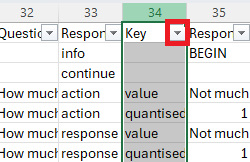
This will bring up a menu which looks something like this:
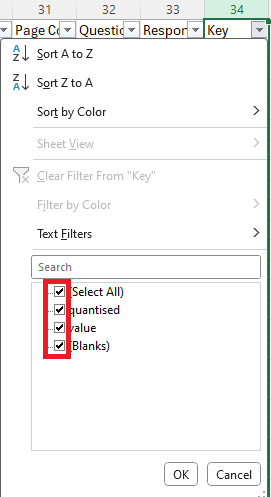
Notice all the ticks in the boxes? At the moment, all our data is selected and is being displayed.
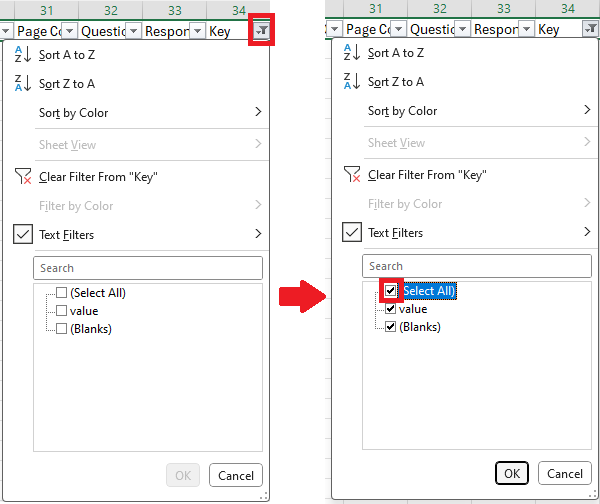
- Uncheck the '(Select All)' box (this will deselect all filters).
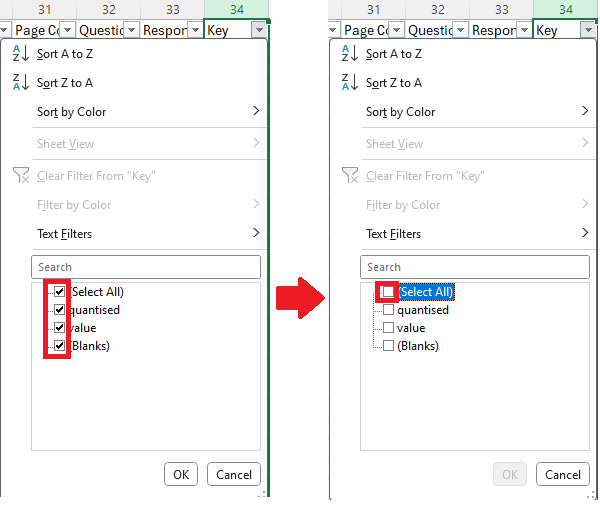
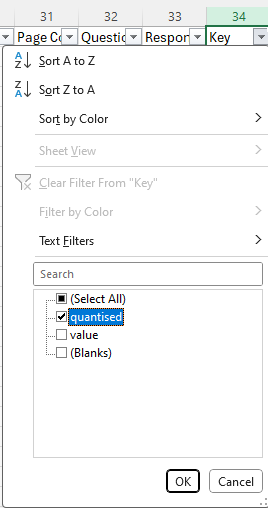
- Next check only the data we want to remove and press 'OK'. i.e. select 'quantised'. (In Questionnaire Builder 1, you will have to select every box that corresponds to quantised data - these will be in the form 'questionkey-quantised'.) Your filter box should now look something like this:
Your data spreadsheet will now look something like this:
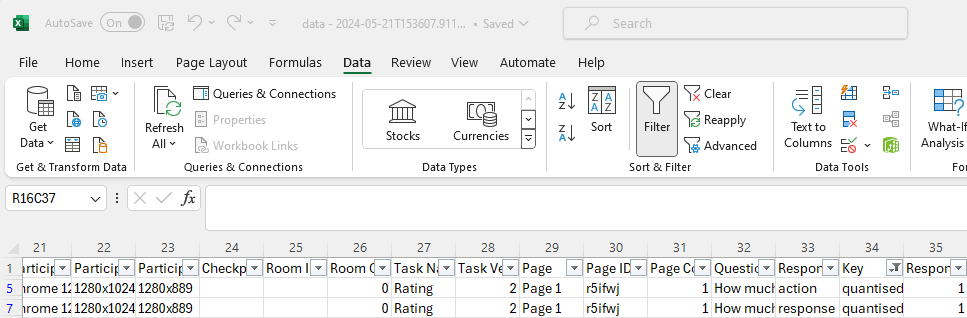
Notice how only the quantised data is being displayed on your spreadsheet. (In this example there are only two rows; you will likely have more participants and thus many more rows.)
- Now highlight all the rows of data: Make sure you highlight the whole row by clicking on the row number itself. To quickly select all rows, first click the top row of data, then hold the SHIFT key ( on your keyboard) and press the last row of data. This will select all the rows between the two points.

- Now while keeping the rows selected, right-click on the any of the row numbers and select 'Delete Row' from the menu.
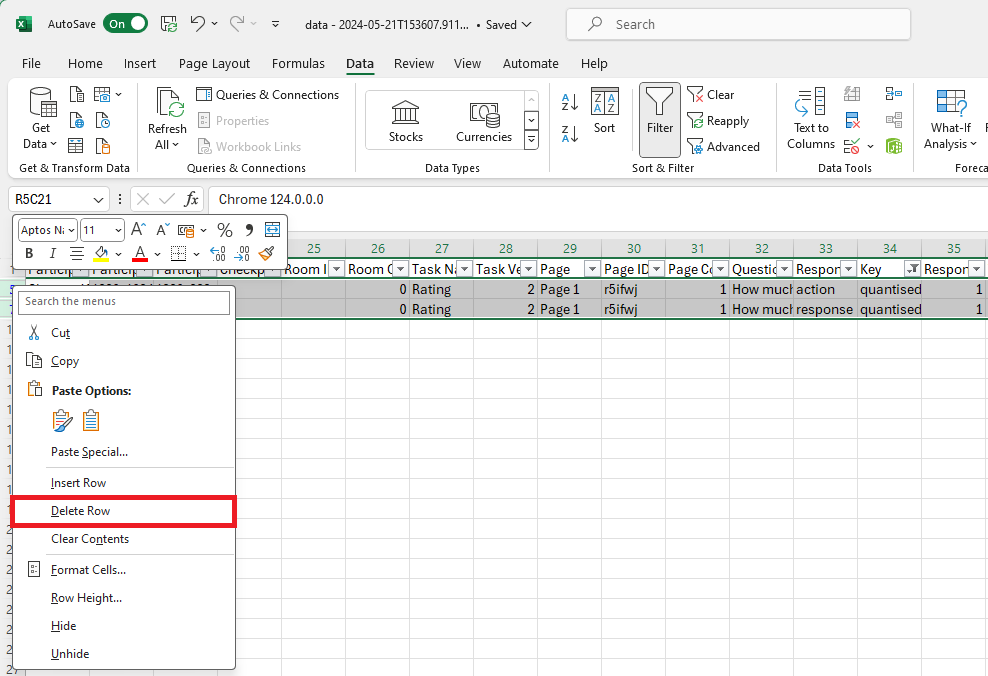
You should now be left with a seemingly blank looking data sheet:
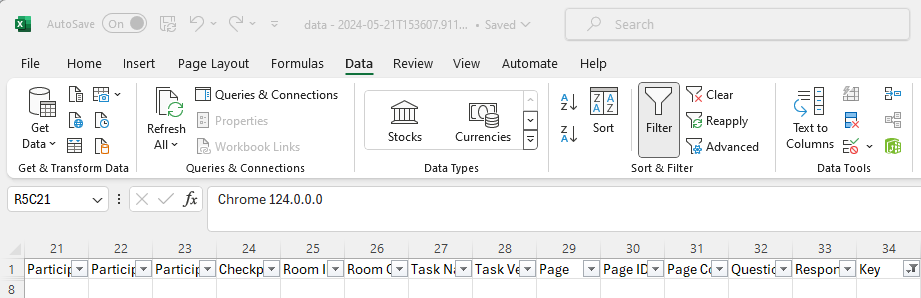
- Finally, remove all the filters and we have our cleaned questionnaire data! Click again on the 'Key' filter arrow, check '(Select All)', and press OK:
Your data sheet will now look like this:
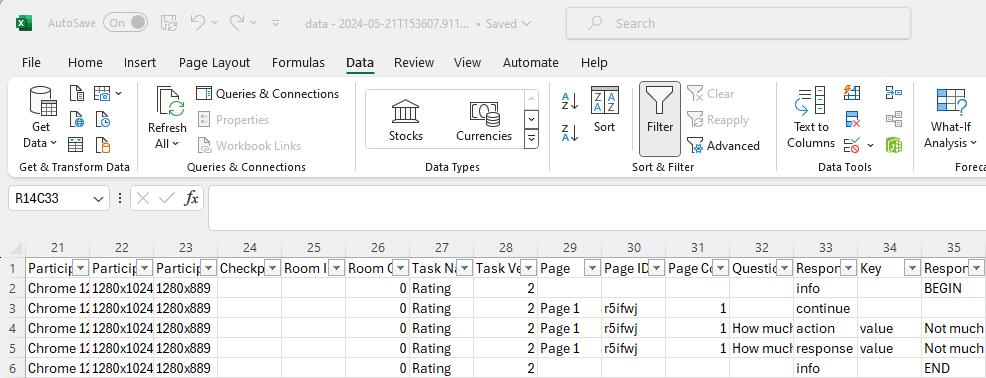
Your data no longer contains any ‘quantised’ data rows!
Excel Pivot Tables
If you're not familiar with Pivot Tables, get ready to revolutionise the way you edit your data! Pivot Tables are an incredibly useful way to get your data into the format you want it in. For instance, you can ask Excel to calculate the mean of each participant's score over a series of trials, and enter those means into a new table where each participant has one row.
Learn the basics of Pivot Tables for transforming task data from long to short format in the video below!
NB: The below video was made using data from the Legacy Tool Task Builder 1. The information contained is still accurate, but some of the column names will be a little different. For example, you'll no longer see the columns 'Zone Name' or 'Zone Type' because Task Builder 2 doesn't use zones. In Task Builder 2 data you'll find the same sort of information in the 'Object Name', 'Component Name', and 'Response Type' columns instead.
Length (mins): 4:18
Combining Task and Questionnaire Data in Excel
When you generate your Gorilla data, you can choose to automatically combine data across all tasks or across all questionnaires. However, sometimes you might need to combine data from a task with data from a questionnaire into one Excel file. Learn how to do this in the video below!
If you are planning to use SPSS for your data analysis, have a look at their guide to merging files for SPSS-ready data.
NB: The below video was made using data from the Legacy Tool Task Builder 1. The information contained is still accurate, but some of the column names will be a little different. For example, you'll no longer see the columns 'Zone Name' or 'Zone Type' because Task Builder 2 doesn't use zones. In Task Builder 2 data you'll find the same sort of information in the 'Object Name', 'Component Name', and 'Response Type' columns instead.
Length (mins): 3:29
Advanced Data Handling in Excel - Pivot Tables and Text Responses
One downside of pivot tables is that they don't allow you to pivot text responses. However, this is are ways to get around this using Excel functions. We'll take you through a couple of ways this could be achieved, including a nifty solution using the INDEX and MATCH functions, just like we used in the Combining Data video. Watch the video below to find out how to emulate pivot tables this way!
NB: The below video was made using data from the Legacy Tool Questionnaire Builder 1. The information contained is still accurate, but some of the column names will be a little different. For example, you'll no longer see the column 'Question Key'. In Questionnaire Builder 2 data you'll instead find similar information in the 'Object ID' and 'Key' columns.
Length (mins): 9:27
Worked Examples of Data Preprocessing
You can find worked example of data preprocessing using Excel in our Gorilla Academy!
See our lecture on organising data in Excel to learn about Excel formulas to calculate new variables and creating pivot tables to prepare your data for analysis!
Mousetracking Data to Plots in R
NB: This guide relates to mousetracking in the Legacy Tool Task Builder 1. Mousetracking is now available in Task Builder 2, and this guide will be updated in the near future.
This guide contains code for converting Gorilla mouse-tracking data to mousetrap format and using mousetrap() functions to create plots.
Make sure that all the individual mouse-tracking files (in xlsx format) are together in the same folder with no other unrelated xlsx files. If you've kept the raw data in the same format it was downloaded from Gorilla in, this should already be the case.
To use the script below, copy and paste all of it into the top left-hand section of your new RStudio script. Then follow the instructions written in the comments of the script itself (comments begin with a “#”).
Pressing CTRL+ENTER will run the line of code you are currently on and move you onto the next line. Making your way through the code using CTRL+ENTER will allow you to see how the dataset gradually takes shape after every line of code. CTRL+ENTER will also run any highlighted code, so if you want to run the whole script together, highlight it all and press CTRL+ENTER. You can also press CTRL+ALT+R to run the entire script without highlighting anything.
For more information about Gorilla please consult our support page which contains guides on columns found in your data.
Analysis of Eye Tracking Data using R
For more information on how to analyse eye tracking data in R with Task Builder 1, visit our TB1 eye tracking pages.
While we do not currently offer specific guidance on how to analyse eye tracking data in R with Task Builder 2, you can find general information about the structure of the data and tips for analysis in our TB2 eye tracking guide.